
If you're going paperless, you'll need an easy way to make your scanned documents searchable so they're more than just static pictures of your paper documents. We've already looked at ways to OCR documents in apps such as Adobe Acrobat, PDFPen, and Google Drive. Though each of these apps can recognize text in your documents, it's not their primary function.
Perhaps one of the most well-known OCR developers is ABBYY, which produces many different paperless management programs. In this tutorial, I'll show you how you can use their web app FineReader and its OCR technology to convert PDFs, scans, and other image files into editable text.
The ABBYY FineReader Advantage
Even though the online version is not nearly as powerful as the desktop version, ABBYY FineReader Online is perhaps the most powerful online OCR service available now.
Pre-Processing
ABBYY FineReader takes out most of the work that would have had to be done in order for OCR to be successful in another service, as pre-processing is done in the app itself. ABBYY FineReader corrects image distortions, such as page orientation and noise, before starting the scan. Of course, aspects such as brightness and image quality are dependent on the user, but no further editing would be necessary on the user’s end.
The Scanning Process
After pre-processing, ABBYY FineReader breaks down the document into elements such as tables, images, and blocks of text before detecting lines and individual letters and words. The technology then determines the relation of all properties of the page to each other. This is to ensure accurate replication not only of the text in the document, but the entire layout of the page itself.
Language Support
ABBYY FineReader Online currently supports 42 languages, even those with non-Latin characters such as Hebrew and Korean. There is dictionary support for 37 of those languages, which helps create an even more accurate recreation by checking detected words in at least one dictionary. The service is capable of OCR on documents with up to three different languages at a given time.


In addition to language support, the service can scan old texts in German and Latvian that were set in black letter, making ABBYY FineReader Online a viable option for the OCR of historical documents.
The Cost
A service this powerful doesn’t come without a price. OCR on ABBYY FineReader Online isn’t all too pricey: page credits cost between $3-$10USD for increments of 20-200 page credits respectively. However, you get 20 page credits for free upon signing up for the service.
The OCR Process
Once you've signed into your ABBYY FineReader Online account, you will be redirected to the uploading page.
Getting Started
First, find the document or image you want to upload, and make sure that ABBYY FineReader supports OCR for your file. The service supports OCR for PDF, .jpg, .png, .bmp, .pcx, .dcx, .tif, .gif, and .djvu files. Maximum file size is 30MB.
Tip: For the best results, make sure your file is high quality, and the size of the text is at least 9pt or 10pt.
If you want to OCR a physical document, use a hardware scanner, such as Doxie, or a mobile app to convert the physical document into an ABBYY FineReader-compatible file format.
Uploading the Document
Once your document is ready for upload, click the Upload button under the Load a file to process field. Find your file in the Finder window, and click Open. I'd recommend checking off the Send me a download link by e-mail box just below the file field for easy access to the recreated document after it has been OCRed. The uploaded file appears in the Select files to process field a few sections below.


Next, define the languages of your document under the Select the language(s) of your document field. Scroll through the list until you find the languages of your document. If you have more than one, select the additional languages by holding the Command key, if you use a Mac, or the Control key, if you use a PC, and clicking.


If you are scanning an older document that was set in black letter, click the hyperlink to the right of the language selection box. The language list will change and offer you the proper German and Latvian options for OCR.
Then, go to the Select an output format field to select the format to which the file will be OCRed. At this time, ABBYY FineReader Online can export the files as Microsoft Word or Excel (in both the 97-2003 and new version formats), Open Office, PDF, RTF, or Plain Text documents. Pick the format you want the final document to be converted to from the drop-down menu.
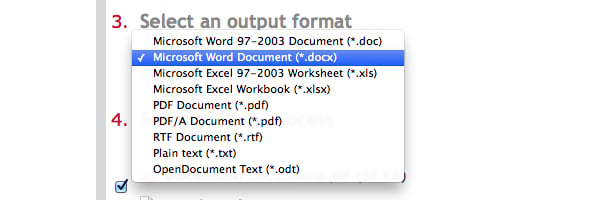

Tip: When selecting your document output, be wary of tables, charts, and other images that may be in your input document, as the word processor may not be able to handle them properly and yield poor results.
Make sure the documents you want OCRed are checked off in the Select files to process field. Now, press the Recognize button, and ABBYY FineReader will begin OCR.


Processing the Document
After pressing Recognize, you will be redirected to the Task History page, where you'll be able to check up on the progress of the OCRed document. Depending on the size of the file, OCR can take anywhere from a few seconds to few minutes.


Once processing ends, you're able to download your document in the format you selected, as well as export the document directly from the web app to Google Drive, Evernote, and Dropbox. You can also rate the quality of the OCR job, which allows ABBYY to improve their products.


OCRed documents remain on ABBYY FineReader's server for two weeks before they are automatically deleted.
Now Get to Work!
ABBYY FineReader Online is an easy way to OCR complicated documents on the web for a low cost. While it is not completely perfect while dealing with images and other stylistic elements, it translates text flawlessly, even in documents with more than one language, into many different editable file formats.
If you have any issues with OCR in ABBYY FineReader Online, or any thoughts or concerns about OCR or going paperless in general, leave a comment down below!
 By
By









